在做数据挖掘项目时,拿到数据,首先要分析问题和观察数据,我在“观察数据”这一阶段主要是看看有没有直观的数据规律以及异常点,对于那些特征维度较低的数据,比如仅仅2维,我选择画散点图观察,高纬度数据可以用t-SNE降维后再画图。除了可视化,聚类算法也是找到异常点的常用手段之一。
这篇博客介绍一种最基本的聚类算法:K-Means。
算法描述与EM
聚类算法的作用是将数据集自动划分为多个不同的集合。 K-Means算法是典型的无监督算法,对于数据集\(D\), 我们设定参数k(k个集合),她就能自动地学习出k个类别,简单又神奇。那么K-Means是如何学习到这k个集合呢?专业一点说就是,K-Means的目标函数是啥?如何优化她的目标函数?先回答第一个问题,下面就是K-Means的目标函数:
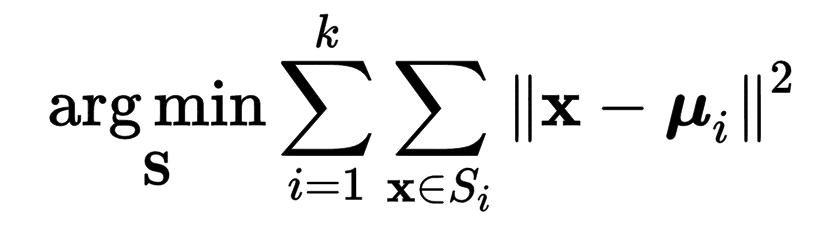
物理意义:我们希望找到的k个集合,每个集合内的点都距离此集合内平均值点最近(每个集合中的点都紧密团结在一起)。
知道了目标函数,下一步就要考虑如何求解,最常见的求解方法是Lloyd算法,也就是使用EM算法,注意,Lloyd算法得到的结果是局部极小值而不是全局最小值哦。
EM算法求解步骤很简单,总共分三步:
- 将所有数据点都分配到某个集合 -> 计算每个点到集合平均值点的欧氏距离
- 计算每个集合内点的平均值 -> 计算每个特征的平均值
- 重复上面两步直到局部收敛 -> 前后两次迭代的集合结果相同
上面的三步概括起来就是 E->M->E->M->………..
import numpy as np
from collections import defaultdict
from random import uniform
class KMeans(object):
"""
kmeans 聚类算算
"""
def __init__(self):
pass
def cluster(self, X, k, initializer="random"):
self.X = X
self.k = k
self.centers = defaultdict(list)
self.assignment = np.zeros(self.X.shape[0]) #记录每个样本属于哪个中心点
if initializer == "random":
self._initialize() #初始化得到k个点
elif initializer == "kmeans++":
self._carefulSeed()
else:
raise ValueError('initializer error!')
self._assign() #将数据集中每个样本分配给最近的中心点
self.next_centers = None
while self.centers != self.next_centers:
self.next_centers = self.centers
self._getcenters()
self._assign()
return self.assignment
def _carefulSeed(self):
"""
kmeans++
1、从输入的数据点集合(要求有k个聚类)中随机选择一个点作为第一个聚类中心
2、对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x)
3、选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大
4、重复2和3直到k个聚类中心被选出来
"""
from random import randint
index = randint(0, self.X.shape[0]-1)
self.centers[0] = self.X[index]
indexs = {index:1} #记录中心点是X中的第几个点(index), 以避免选择相同的点作为类中心
for i in range(self.k)[1:]:
def _initialize(self):
"""
初始化,即初始化k个中心点和每个样本属于哪个中心点
这k个样本点是随机产生的
"""
feature_min_max = defaultdict(list) #保存每个特征值的最小值和最大值
feature_dimensions = self.X.shape[1]
get_min_max = lambda x, y: (x,y) if x<y else (y,x)
for i in xrange(feature_dimensions):
i_min, i_max = get_min_max(self.X[0][i], self.X[1][i])
for j in range(self.X.shape[0])[2👎2]:
tmp_min, tmp_max = get_min_max(self.X[j][i], self.X[j+1][i])#self.X[j+1][i], self.X[j][i] if self.X[j][i] > self.X[j+1][i] else self.X[j][i], self.X[j+1][i]
if tmp_min < i_min:
i_min = tmp_min
if tmp_max > i_max:
i_max = tmp_max
tmp_min, tmp_max = get_min_max(self.X[-1][i], self.X[-2][i])#self.X[-1][i], self.X[-2][i] if self.X[-2][i] > self.X[-1][i] else self.X[-2][i], self.X[-1][i]
i_min = tmp_min if tmp_min < i_min else i_min
i_max = tmp_max if tmp_max > i_max else i_max
feature_min_max[i] = [i_min, i_max]
for i in xrange(self.k):
this_k = []
for j in xrange(feature_dimensions):
value = uniform(feature_min_max[j][0], feature_min_max[j][1])
this_k.append(value)
self.centers[i] = this_k
def _distance(self, point1, point2):
"""
计算点point1 和 point2 之间的欧氏距离
"""
dd = 0
for i in xrange(len(point1)):
dd += (point1[i] - point2[i]) ** 2
return np.sqrt(dd)
def _assign(self):
feature_dimensions = self.X.shape[1]
for i in xrange(self.X.shape[0]):
min_distance = float("inf")
current_assignment = self.k
for j in xrange(self.k):
tmp_d = self._distance(self.X[i], self.centers[j])
if tmp_d < min_distance:
min_distance = tmp_d
current_assignment = j
self.assignment[i] = current_assignment
def _getcenters(self):
"""
计算每个中心点的平均值,作为新的中心点
"""
cluster_numbers = defaultdict(int) #记录每个分类的样本数目
cluster_sum = np.zeros((self.k, len(self.X[0]))) #记录每个分类的所有样本相加之和
for index, center in enumerate(self.assignment):
cluster_numbers[center] = cluster_numbers.get(center, 0) + 1
cluster_sum[center] += self.X[index]
for i in xrange(self.k):
self.centers[i] = list(cluster_sum[i]/float(cluster_numbers[i]))
调包篇
还是以调用sklearn为例,sklearn.cluster.KMeans对应于k-means算法,此外还有sklearn.cluster.MiniBatchKMeans, 顾名思义,就是使用批梯度下降算法优化目标函数,收敛速度会比KMeans快一点,但是结果可能要稍差。